An employee pastes a customer contract into ChatGPT to summarise it before a meeting. A few keystrokes; a fast answer; nothing visible goes wrong. What actually happened: the contract content may now be sitting in OpenAI’s retention store for up to 5 years, and on the consumer tier it may be used to improve future models.
The privacy posture of the major AI vendors changed materially in 2025, and most users haven’t caught up. If your mental model is “Claude doesn’t train on my data, ChatGPT does, Gemini might” — that was true two years ago. As of May 2026, the picture is different, more nuanced, and worse for default consumer accounts than most people assume.
This piece is the operator’s guide: what’s actually true today, the four questions to ask before sending data to any AI tool, and the policy quirks worth knowing.
Where your data goes when you send it to an AI
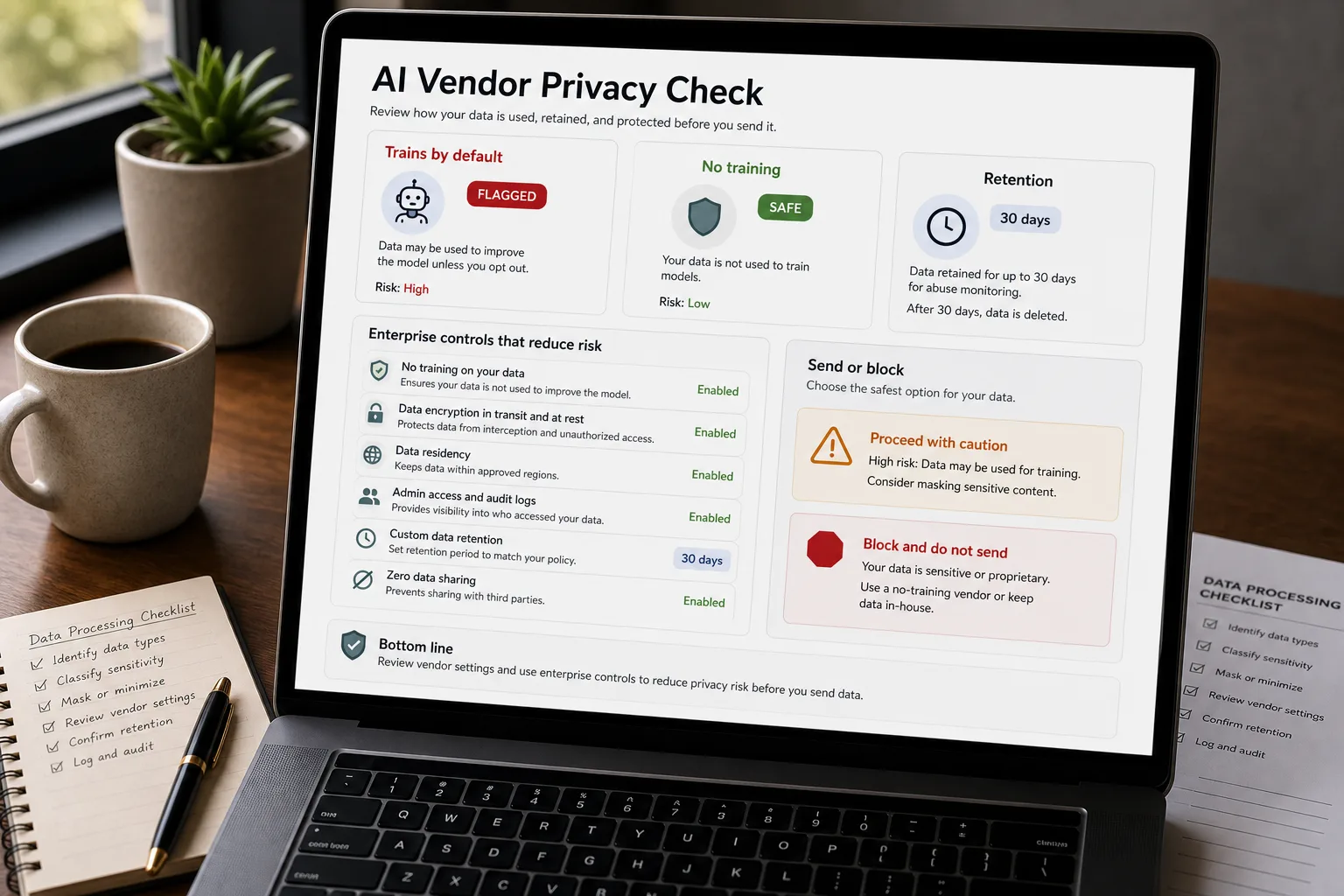
When you paste a document into ChatGPT, Claude, or Gemini, several things may happen — depending on the vendor, the tier, and the settings you may or may not have changed:
- The text is processed on the vendor’s infrastructure to generate a response. This always happens. The data is in motion through their systems.
- The conversation may be retained for some period — for abuse monitoring, debugging, or model improvement. Retention varies from 30 days (most APIs) to 5 years (some consumer plans after 2025 policy changes).
- The conversation may be used to train future models. Whether this happens depends on tier (consumer vs API vs enterprise) and your settings. The default has shifted toward “yes, unless you opt out” for consumer plans across all three major vendors.
- Sub-processors may receive the data — cloud providers, content-moderation services, support teams. Vendor privacy pages list these; few users read the lists.
- The data may be subject to law enforcement requests depending on jurisdiction. All three major vendors publish transparency reports.
None of this is unique to AI — it’s the standard SaaS data lifecycle. What’s new is the model-training step, the volume of sensitive content people paste in casually, and the rate at which vendor policies change.
The four questions to ask before sending data to any AI tool
1. Will my data be used to train future models? This is the single most important question. The answer differs by tier:
- Consumer free / paid plans (ChatGPT Plus, Claude Pro, Google AI Pro): Yes by default for ChatGPT and Gemini; yes by default for Claude as of August 2025 (changed from no — see the next section). All three offer opt-outs in settings.
- API access (without enterprise contract): No by default for OpenAI (since March 2023), no by default for Anthropic, no by default for Google.
- Team / Enterprise plans (ChatGPT Business and Enterprise, Claude Team / Enterprise, Gemini for Workspace): Contractually no, on all three. This is what enterprise pricing buys you. (OpenAI renamed “ChatGPT Team” to “ChatGPT Business” in August 2025.)
2. How long is my data retained, and where? Defaults again vary by tier:
- Consumer: 30 days to several years. Anthropic notably extended Claude consumer-tier retention from 30 days to 5 years in 2025 for users who didn’t opt out of training.
- API: Typically 30 days for abuse monitoring; Zero Data Retention (ZDR) is available on enterprise contracts for sensitive workloads.
- Storage region: Most processing happens in US data centres unless you’ve contracted EU or in-region processing. Matters for GDPR and data-residency requirements.
3. Who else can see my data? Two layers:
- Sub-processors: the vendor’s cloud providers, content-moderation tools, customer-support teams. Listed in the privacy policy.
- Vendor employees: access is governed by internal controls. Audit and access logging are standard at enterprise tier; less transparent at consumer tier.
4. What’s the contractual commitment, and does it match the marketing page? The vendor’s marketing page is not the contract. The Data Processing Addendum (DPA), the Trust Center documentation, and any signed Master Services Agreement are. For sensitive workloads, read those — or ask your vendor for them. If they can’t produce a signed DPA, that’s the answer to whether you should send sensitive data.
Where the major vendors stand in May 2026
The pattern: consumer tiers have weakened (toward training-by-default with longer retention), and enterprise tiers have strengthened (more compliance certifications, ZDR options, BAAs). The gap between the two tiers — in privacy posture, not just features — has widened meaningfully in the last 18 months.
What flipped in August 2025
The notable shift was Anthropic’s August 2025 announcement that Claude consumer users would be opted into training data collection by default unless they actively opted out by 28 September 2025. Retention was extended from 30 days to 5 years for opted-in users. This put Anthropic’s consumer privacy posture roughly in line with OpenAI’s and Google’s, but caught many users off guard — Claude had been positioned and marketed as the “doesn’t train on your chats” alternative since launch.
The lesson isn’t that Anthropic became less trustworthy — it’s that vendor privacy defaults are not stable. They change, sometimes with notice, sometimes quietly. If your team’s data-handling depends on a specific vendor default, write the policy down internally and re-verify the vendor’s stance every 6 months.
What the law requires (and where)
EU AI Act. The high-risk-system provisions become enforceable on 2 August 2026. If you’re an EU business or you provide AI services to EU users, you have obligations: documentation, risk assessment, internal monitoring, and (for some high-risk uses) third-party conformity assessments. Penalties reach up to €35 million or 7% of worldwide turnover for the most serious violations. The regulation is extraterritorial — non-EU vendors serving EU users are in scope.
GDPR. AI doesn’t create a new GDPR regime; it just makes the existing one bite harder. Personal data fed to an AI model is still personal data. You need a lawful basis, a Data Processing Addendum with the AI vendor, and the ability to honour data subject rights (deletion, access, portability). Some of these are operationally awkward when data has already been used to train a model.
US sectoral. No federal AI privacy law as of May 2026, but: HIPAA applies to PHI sent to AI tools (use a vendor with a BAA — others are unsuitable for healthcare); GLBA applies to financial data; FERPA to educational records; FTC enforcement actions are increasingly common against vendors that misrepresent their AI products’ data practices. State laws (California’s CCPA/CPRA, Colorado’s AI Act, others) add another layer.
Where this leaves an operator: if you handle regulated data, you need an enterprise-tier contract with the right BAAs/DPAs in place, in-region processing where required, and an internal record of which AI tools your team is allowed to use for which categories of data. Free-tier ChatGPT is not the right tool for regulated data — and “we’ll handle it case by case” is not a policy.
What to do this week if you haven't yet
For a small team that uses AI tools but hasn’t formalised the privacy posture:
- Inventory. List the AI tools your team uses (formal and informal), the tier each is on, and which data categories each receives.
- Settings sweep. For every consumer account in use, turn off training-data collection. Document that you’ve done so. (Settings change names; here’s where they live as of May 2026: ChatGPT → Settings → Data Controls → Improve the model; Claude → Settings → Privacy; Gemini → myactivity.google.com → Gemini Apps Activity.)
- Sensitive data list. Write down what categories of data should never be sent to a non-enterprise AI tool. Common starters: customer PII, payment data, employee records, internal financials, anything covered by NDAs, anything from regulated industries.
- Enterprise contracts where needed. If your team handles regulated data and is on consumer plans, the upgrade is overdue. The cost gap between consumer and enterprise tiers is small relative to the cost of a privacy incident.
- Re-verify quarterly. Vendor policies change. Calendar it.
FAQ
Is it actually risky to use the consumer tier of ChatGPT or Claude for work?
It depends entirely on what you're sending. For non-sensitive work — drafting marketing copy, asking general questions, brainstorming — the risk is low and the value is high. For anything containing customer data, internal financials, employee information, or regulated content — yes, it's risky. The right answer is usually "upgrade to the enterprise tier for the team that handles sensitive data; consumer is fine for the rest."
What's the difference between "won't train on my data" and "won't retain my data"?
Training is what the model learns from; retention is what's kept on disk. A vendor can not-train and still retain (e.g. for 30 days of abuse monitoring). "Zero Data Retention" is the strongest commitment — your inputs and outputs are processed and discarded. Most enterprise plans offer not-train by default; ZDR is usually a paid upgrade for the most sensitive workloads.
If a model was trained on my data before I opted out, is it gone?
No — and this is one of the genuinely awkward things about AI privacy. Training shapes model weights in ways that can't be selectively undone. Vendors comply with deletion requests for stored data (chat history, fine-tuning files), but data already incorporated into a model's training is effectively permanent. Consequence: "opt out before you start" matters; "opt out after months of paste" is closing the door late.
Are the API and the consumer interfaces really different?
Yes, materially, on every major vendor. The API tier is built for developers and contractually does not train on data by default. The consumer interface is built for individual users and (currently) does train by default. The same underlying models are accessed both ways, but the data-handling contracts are different. If your team is building a product on top of an AI model, use the API — both for technical reasons and because the privacy posture is stronger.
Should we self-host an open-source model for privacy reasons?
Sometimes yes, often no. Self-hosting (Llama, Mistral, Qwen, DeepSeek) gives complete data control — nothing leaves your infrastructure. The trade-offs: model quality is below the proprietary frontier, and you take on the operational burden of running inference reliably. Right answer for highly regulated content (healthcare, classified) or jurisdictions with strict data-residency rules. Overkill for general business use where an enterprise contract with a major vendor handles the privacy concerns.
Can I trust the vendor's privacy claims?
More than informal startups; less than legal documents would suggest. The major vendors' enterprise commitments are contractually binding and audited (SOC 2, ISO 27001), so the contracts mean what they say. The consumer tier is governed by terms of service that the vendor can change unilaterally — and has, multiple times. The trust calculus is different at each tier; treat them differently.