A 2025 MIT study reviewed 300 publicly disclosed enterprise AI deployments and found that only about 5% had generated measurable P&L impact. The headline framing — “95% of AI projects fail” — has been quoted to death. The framing buries the more useful insight.
The interesting question isn’t why most projects fail. It’s which kinds of projects fail. Once you look at the failed cases, a clear pattern emerges. Most “AI failures” are AI being applied to a problem that a different tool would have solved more reliably, more cheaply, and more boringly. This piece is the catalogue of those categories — read it before approving the next AI proposal that crosses your desk.
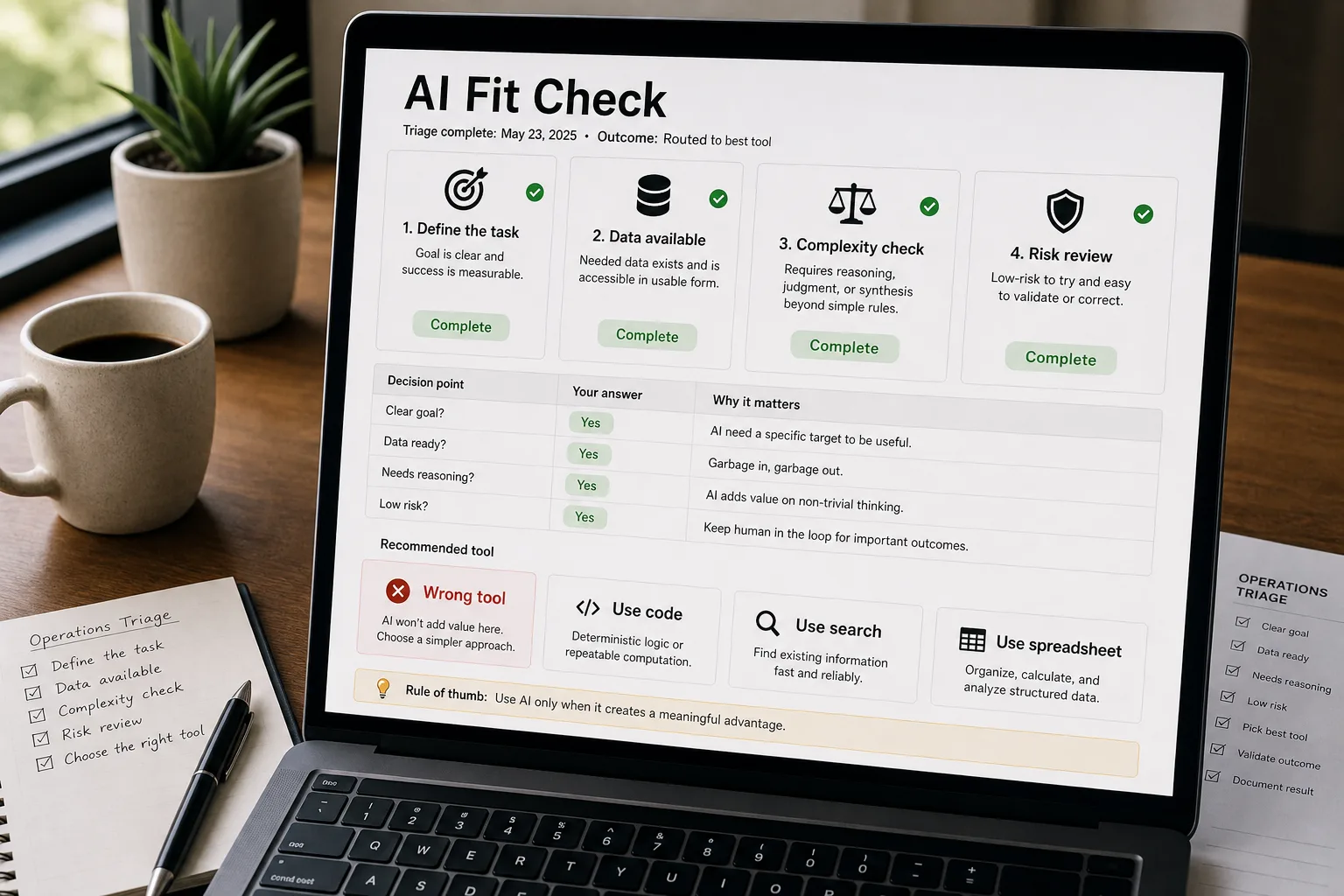
The one-line test
If the answer must be exactly right, every time, with no human review — AI is probably the wrong tool. Use code, a database query, or a calculator.
Everything below is a more detailed version of that test, organised by the categories of work where you’ll most often see AI mis-applied.
Deterministic transformations
Converting currency, computing tax, calculating compound interest, transforming a CSV into a different CSV format, parsing a date string, validating an email address. These tasks have one correct answer, the rules are knowable in advance, and a small amount of code will produce that answer 100% of the time.
An LLM will produce the correct answer most of the time. The combination of “mostly right” with “looks right when wrong” is exactly the failure shape that costs the most to debug. If your team is using GPT to compute totals on an invoice, that’s the wrong tool — you have a sum function.
Use instead: A calculator. A spreadsheet formula. A few lines of Python or JavaScript. A database aggregate query.
High-precision, high-stakes decisions
Medication dosing, legal contract terms, regulatory filings, financial reporting numbers, anything that goes into an audit trail. These tasks share two properties: the cost of a wrong answer is high, and the wrongness may not be discovered for months.
LLMs are not safe-by-default in this category. They produce confident, fluent, plausible answers — which means a wrong answer is harder to spot than a wrong answer from a tool that visibly shows its work. A junior accountant entering a number wrong is easier to catch than an LLM confidently proposing the same wrong number with three paragraphs of fluent justification.
This isn’t a “never use AI here” rule — AI can speed up drafting, summarising, and surfacing precedents. It’s a “never let AI make the final commit here without a human-in-the-loop checkpoint” rule.
Use instead: AI as a drafting assistant; a qualified human as the deciding authority; structured tools (decision trees, formal verification, calculation engines) for the deterministic parts.
A simpler tool already exists
Searching across files (grep / ripgrep). Counting things in a database (SELECT COUNT(*)). Extracting structured fields from a known format (a regex, an XPath, a JSON path). Renaming files, batch-resizing images, deduplicating a list. The classic engineering toolbox solves all of these in deterministic, debuggable ways.
The temptation to “just ask Claude” is real and corrosive. The output is usually right; when it’s wrong, it’s silently wrong; the cost adds up; and the team’s existing skills atrophy. Use AI to learn the simpler tool (“write me a regex that does X”), not to replace it at runtime.
Use instead: SQL, regex, shell scripts, the standard library of whatever language you already use, established CLI tools.
Real-time, low-latency, high-volume decisions
Fraud detection at the moment of transaction, ad bidding, autocomplete on every keystroke, content moderation at platform scale. These workloads need decisions in milliseconds, at thousands or millions per second, with cost-per-decision in fractions of a fraction of a cent.
LLM inference is too slow and too expensive for this category. Even the cheapest LLM API calls take hundreds of milliseconds and cost ~$0.0001 per call — multiply by a million decisions per day and the bill becomes a planning constraint while the latency makes the user experience poor. The right tools here are classical machine learning models — small, fast, purpose-built classifiers trained on your specific data — or rule-based systems for the truly deterministic parts.
Use instead: Purpose-built ML classifiers, gradient-boosted trees, embeddings + simple rules, or rule engines. AI may have a role in training or labelling data for these systems — but not in the hot path.
Voice and speech in noisy environments
The Yum! Brands AI ordering rollout — drive-throughs at KFC and Taco Bell — is the public reference case. The system worked in clean conditions and broke in real ones: thick accents, background noise, multiple voices, edge-case orders. The company eventually rolled it back to a hybrid model with humans monitoring during busy periods.
Speech recognition has improved enormously and continues to improve, but the combination of imperfect audio input, free-form speech, and irreversible action (placing an order, scheduling an appointment, processing a payment) is still where deployments most reliably embarrass their owners.
Use instead: Hybrid models with fast human escalation for low-confidence transcriptions; structured input flows where users confirm before commit; voice for transcription only with a separate human or rule-based step for the action.
Tasks requiring consistent output across runs
Generate a 200-word product description for each item in a catalogue, then run the same prompt next quarter when descriptions need a refresh — and watch the tone, structure, and emphasis drift. LLMs are non-deterministic by design. Even with temperature=0, prompt sensitivity and model-version drift mean that “the same prompt” in March and September can produce noticeably different outputs.
This matters for catalogues, templated documents, regulatory disclosures, and anywhere consistency across runs is part of the spec. The fix is to constrain the structure — JSON schemas, fixed templates, structured outputs — and to treat the LLM as a fill-in-the-blanks helper rather than a free-form writer.
Use instead: Templates with named slots filled by an LLM. JSON-schema-constrained outputs. For truly templated content (legal boilerplate, structured product data), traditional templating engines.
Information the model cannot access and you cannot supply
If the answer depends on data that’s behind a login the model doesn’t have, in a system the model can’t query, or that exists only in someone’s head — and you haven’t built a path to give it to the model — you’ll get a confident guess. The model will not say “I cannot access this.” It will produce something that looks like the right shape of answer.
If the answer depends on data the model could be given — your wiki, your tickets, your transcripts — then the right move is RAG (see Build a private knowledge base). If the answer depends on data nobody has yet, AI cannot generate that data.
Use instead: Build a retrieval layer if the data exists. Build a data-collection process if it doesn’t. Don’t ask the model to fabricate answers from missing inputs.
What AI failure actually looks like in production
The pattern in the post-mortems is consistent enough to be a heuristic: when AI fails publicly, the failure is rarely the model. It’s the application — a problem the model was never the right tool for, deployed on a timeline that didn’t allow for the test cases the production environment would generate.
A practical posture
Choosing the right tool is unglamorous. “We used a SQL query and a regex” doesn’t fund-raise. But the projects that survive contact with reality are the ones where AI is used for what it’s actually good at — text-in-text-out work where a draft beats nothing and a human reviews before consequences — and where simpler tools are used for everything they handle better. (See What an LLM actually does for a business for the positive version of this.)
Before adopting an AI solution, ask: what tool would I use if AI didn’t exist? If the answer is “code I could write in an afternoon” or “a SQL query,” start there. If the answer is “I’d ask a person to read this and write a draft,” now AI is plausible.
FAQ
But the model gets it right most of the time. Isn't that good enough?
Depends entirely on the cost of being wrong. For a draft email a human will read before sending — yes, 95% accurate is great. For a tax calculation, an invoice total, or a medication dose — no, 95% means 5% of outcomes are wrong, and the wrongness is harder to detect than a tool failure. Match the tool's reliability profile to the problem's tolerance for error.
What about AI agents that can take real-world actions?
Same rule, more sharply. The cost of "agent does the wrong thing" includes whatever the action affects — sent emails, booked travel, deleted files, executed trades. As of 2026, the published case studies (Amazon AI agent destroying production data, several smaller incidents) suggest agentic systems need narrow, sandboxed scopes and human approval gates for irreversible actions. Treat "AI can take action" as a separate, much higher-risk category than "AI generates text."
Doesn't this contradict everything else in this playbook?
No. The playbook says "here's how to use AI well for tasks where it's the right tool." This piece says "here's how to recognise the tasks where it isn't." Both are necessary. The expensive failure mode for an organisation is enthusiastic AI adoption with no instinct for which problems should be solved differently.
How do I push back on a leader who wants to add AI to everything?
Reframe the question. Instead of "should we add AI to X?", ask "what's the simplest possible solution to X, and what's the cost of being wrong?" If the simplest solution is a SQL query, start there. If the cost of being wrong is high, plan for human review even if AI is involved. The leader rarely wants AI for AI's sake — they want the outcome AI is supposed to produce. Keep the conversation on the outcome.
What's the most under-rated alternative to an LLM?
A regex with a comment explaining what it does. Sounds glib, but it isn't — a substantial fraction of "we used GPT to extract X from Y" projects could be replaced by 12 lines of code that work deterministically and never have a model-version-drift bug. The other underrated alternative is asking a person — sometimes the answer to "can AI solve this?" is "yes, but a 20-minute conversation with the right colleague would solve it faster."