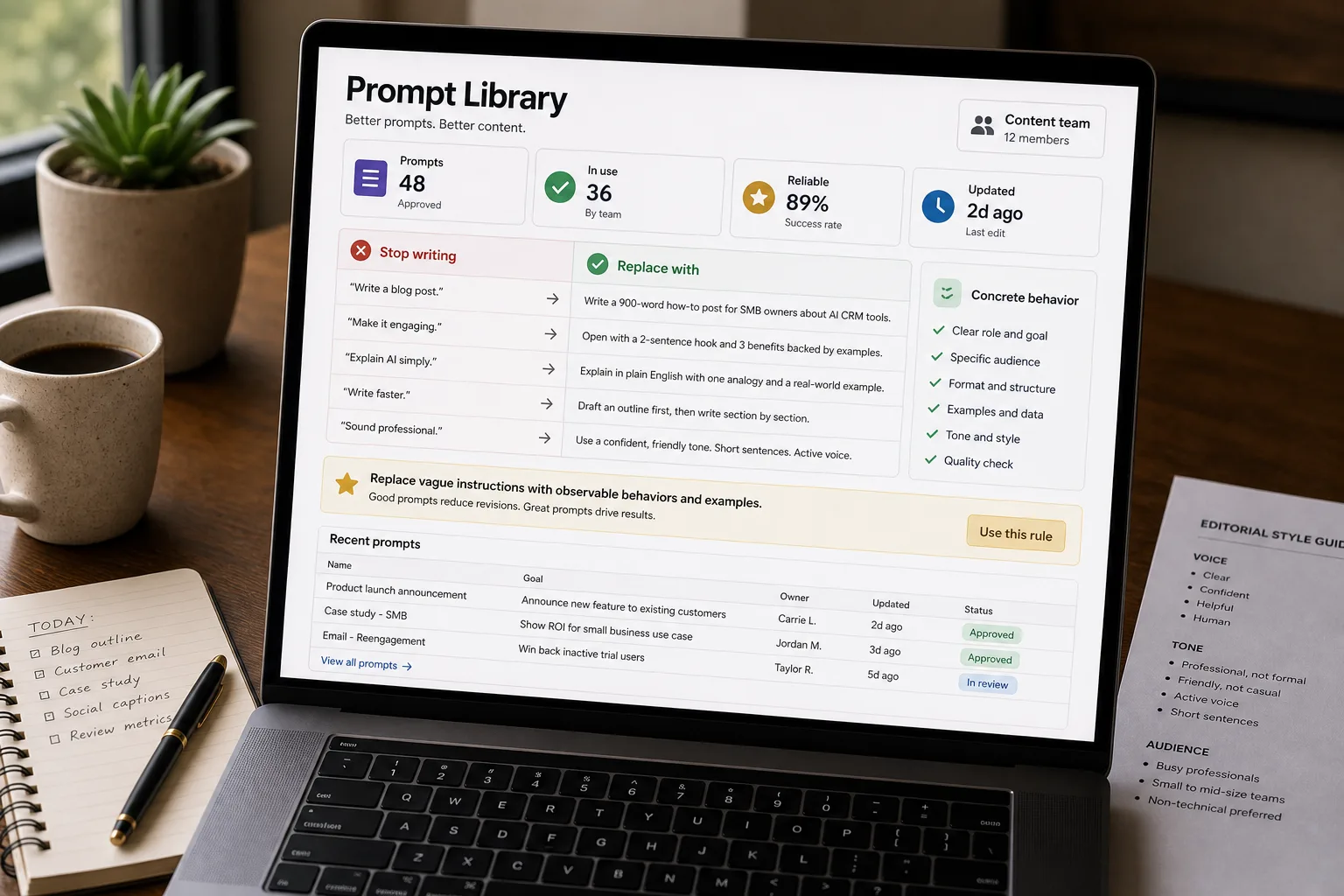
If you manage a content team using AI to draft, the honest reason most of the output reads as generic AI prose is that the prompts themselves are generic. “Write a 500-word blog post about X” is a brief that gives the model nothing specific to grip onto — no audience, no voice, no purpose, no constraints. So it returns the average of everything it has read on X, dressed in the model’s house voice.
The fix is not a smarter model. The fix is a better prompt, built from a small number of reusable patterns. Five of them, each with a job, designed to be combined rather than used alone.
A team that internalises this set produces drafts that don’t read as generic AI work, in roughly the time it takes to write the brief — which is the time you would have spent on the brief anyway.
The five that matter
Role priming. Tell the model who is writing. Not “you are a helpful assistant” — that gets you the model’s default voice. Be specific: “You are a senior editor at The Atlantic, ten years writing long-form business journalism, known for a calm narrative voice and short opening paragraphs.” The role frame conditions everything downstream — vocabulary, sentence rhythm, the kinds of evidence the model surfaces.
Context packing. Paste your own writing into the prompt. Not as inspiration — as the model’s reference. Three or four paragraphs of past work you’d be happy to publish again, prefaced with “This is the voice. Match it.” The model pattern-matches to samples better than to any list of adjectives. A team that maintains a small library of voice samples in a Claude Project or Custom GPT amortises this step over every draft.
Format constraints. Be explicit about shape. Exact word count, section structure, banned phrases (“don’t use ‘leverage’, ‘unlock’, ‘powerful’, or em-dashes”), required elements (“include one specific number, one specific year, and one specific person’s name”). Constraints reduce the editing load by half because the draft arrives shaped, not as raw prose that needs sculpting.
Voice training. A short voice guide prepended to the brief: three to five sentences describing tone, sentence length, what your brand does not say, and the editorial values that shape decisions. “We don’t hedge with adverbs. We don’t use ‘simply’ or ‘just’ as softeners. We never claim something is ‘easy’ unless we can demonstrate it. We end with a concrete next step, not a flourish.” This is where the model learns the editorial standard, not just the voice.
Iteration scaffolds. Don’t ask for a draft and stop. Ask the model to draft, then critique its own draft against specific axes (clarity, specificity, voice, banned phrases), then revise. The mistake is to wait until you read it; the better workflow is to make the model do the first editing pass. The output of one critique-revise loop is consistently better than the output of one draft, and the marginal cost is a few extra seconds.
When to use which — and how to combine
The patterns compose. Different jobs need different combinations.
Marketing landing page — role priming + voice training + format constraints. The role primes for the audience, the voice training prevents AI tells, the format constraints (word count, banned phrases, required CTA shape) shape the draft. Context packing is optional; iteration scaffold is overkill at this length.
Blog post draft — context packing + voice training + iteration scaffold. Long-form writing is where voice drift shows up most; the context packing anchors the model to your samples, the voice training names the editorial standard, the iteration scaffold catches the first round of AI tells before you see them. Format constraints matter but are looser at length.
Press release or formal announcement — role priming + format constraints + iteration scaffold. Press writing is structural — date, location, quote, supporting details, boilerplate — and the format constraints carry most of the load. Role priming sets the tone (formal, factual, restrained); iteration catches generic phrasing.
Ad copy or headline variants — role priming + format constraints. Short-form work is where the model’s default voice does the least damage; constraints are the main lever. Ask for variants with explicit angles (“one funny, one earnest, one urgent”) to force genuinely different framings rather than three rewordings of the same thing.
Social media — context packing + format constraints, with the platform character limits enforced explicitly. The voice from your past posts is what makes social copy recognisable; without context packing, every brand sounds like every other brand on the platform.
What this changes in practice
The pattern-applied draft is not the published piece. It is the draft your editor was hoping for. The win is that more of editorial time goes to judgement and less to first-draft cleanup.
The instructions to stop writing in your prompts
A short list of instructions that read fine but produce nothing useful, with why:
- “Be creative.” The model has no idea what creative means in your context. Replace with: “Take an unusual angle — start from the consequence, not the cause.”
- “Make it engaging.” Engaging is a property of writing, not an instruction. Replace with: “Open with a concrete scene. Make me curious by the third sentence.”
- “Write in a friendly, conversational tone.” Every brief says this. The model returns its default friendly conversational tone, which is everybody’s friendly conversational tone. Replace with: voice training (the third pattern).
- “Avoid AI-sounding language.” The model does not know what sounds AI to you. Replace with: a specific banned-phrase list (“don’t use these eight phrases”), updated when you spot new ones.
- “Use simple language.” Calibrates to nothing specific. Replace with: a reading-grade target (“write for a smart 15-year-old”) or a sentence-length constraint (“short sentences; never more than 22 words”).
The pattern is the same in every case: replace abstract adjectives with concrete behaviours. Models execute concrete behaviours; they pattern-match abstract adjectives to whatever they have seen called by that adjective most often.
Related work
For the broader workflow of first-draft copy with the patterns applied, see First-draft marketing copy without the AI tells. For the longer comparison of AI writing tools that wrap these patterns into a UI, see AI writing tools compared. For the pipeline that repurposes long-form content with the patterns in mind, see Repurpose a podcast episode into pieces.
FAQ
Should I share my prompt library publicly?
Probably not, for two reasons. First, your library is partly your competitive advantage — the prompts that work for your team's voice took real work to refine, and giving them away erodes that. Second, prompts are pattern-matchers, not magic — a published prompt out of context loses much of its value because the voice samples and the editorial standard live in your team's heads, not in the prompt itself. Share the *pattern set* (this piece is one); keep the specifics internal.
Do these patterns work the same across models?
Patterns work across all major models — Claude, GPT, Gemini — because the underlying mechanism (conditioning on context, attention to instructions) is shared. The *strength* of each pattern varies a little. Claude follows voice samples slightly more reliably than ChatGPT in our experience. ChatGPT follows banned-phrase lists slightly more aggressively than Claude. Gemini benefits more from explicit structure than from voice samples. Treat the patterns as universal and the tuning as model-specific.
How long should a system prompt actually be?
Long enough to specify what matters, short enough that the model still reads it carefully. Empirically: 300–800 tokens for the system prompt covering role + voice training + banned phrases works well across models. Beyond ~1,500 tokens, returns diminish — attention dilutes and the model is more likely to forget specific instructions mid-output. If you find yourself writing a 2,000-token system prompt, that's a signal to split it: a stable base + a per-task brief.
What about "AI tells" — can prompts remove them?
Partially. Banned-phrase lists reliably remove the most common surface tells (em-dashes, "delve", "realm", "unlock"). They don't remove the deeper tells — tricolons, structurally identical paragraphs, over-balanced sentences, formulaic conclusions. Those require an editorial pass to catch and rewrite. The honest framing: prompts get you closer to clean copy; the editor closes the last 10%. Anyone who tells you a prompt alone removes all AI tells has not edited enough AI output.
Should every writer on the team use the same prompts?
The base library — yes. Voice samples, banned phrases, role frames — those are team-level standards. The brief content for each piece — no. Briefs are per-task; each writer should still bring judgement about angle, evidence, and structure. The mistake is to standardise too much (every piece sounds identical) or too little (every piece sounds like a different writer). The library codifies what should be consistent and leaves the rest to the writer.