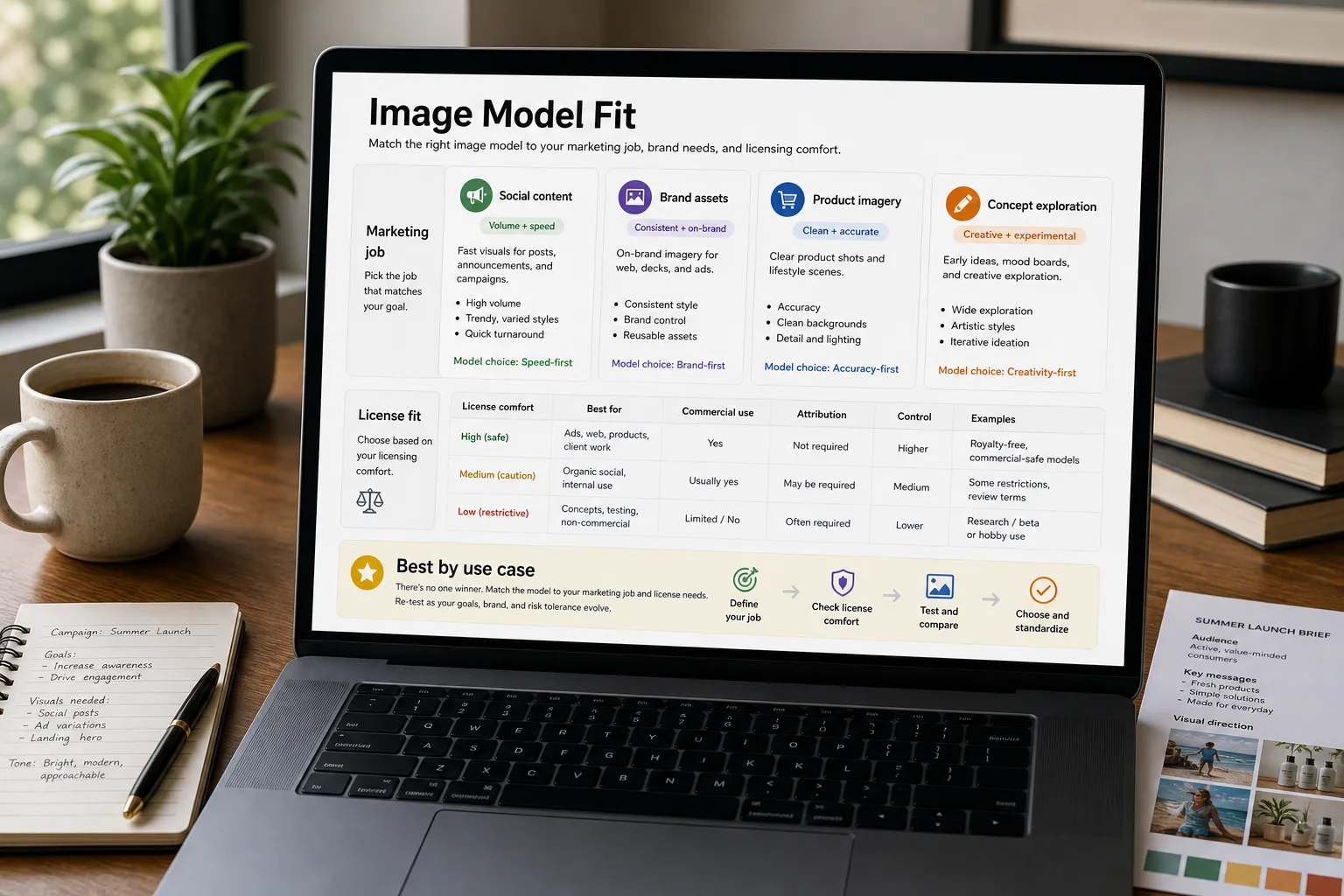
If your marketing team has tried to pick an AI image generator recently, you already know the catalog has grown faster than the clarity. Midjourney has the strongest aesthetic but the most restrictive licensing. Flux has caught up on quality with friendlier commercial terms. SDXL is the free open-source option with a real ecosystem. Imagen integrates with Google’s stack. OpenAI’s gpt-image-2 (April 2026) closed most of the quality gap with the leaders and now sets the bar for text rendering inside images.
Each has a place. Picking the wrong one for your use case produces creative that’s off-brand, expensively priced, or legally questionable.
This piece compares them side by side, with honest aesthetic notes, licensing fine print, and decision rules that map use case to model choice.
The comparison matrix
| FLUX (1.1 Pro / 2 line) | Midjourney | SDXL (open source) | Imagen 4 / Nano Banana | gpt-image-2 | |
|---|---|---|---|---|---|
| Aesthetic quality (subjective benchmarks) | Among the strongest in 2026; FLUX.2 (flex/pro/max/klein variants) is current flagship, FLUX 1.1 Pro still widely available | Long-time leader on stylised aesthetic; v6/v7 refined further | Strong open-source baseline; quality below the top three on out-of-box generation | Strong; Imagen 4 Ultra and Nano Banana (Gemini 2.5 Flash Image) current flagships | Strong — gpt-image-2 (April 2026) is a major step up over gpt-image-1; native 2K output; competitive with the leaders |
| Photorealism | Excellent — FLUX Pro is a current leader | Very good; not the strongest at strict photorealism | Good with the right LoRAs and tuning | Excellent — Imagen 4 strong on photorealism | Very good — gpt-image-2 markedly improved hands, faces, lighting, and material detail |
| Text rendering inside images | Strong — significant improvement over earlier diffusion models | Reasonable but inconsistent; often needs retries | Weak by default; improved with specialised models | Good; Imagen has invested heavily in text accuracy | Category leader — gpt-image-2 reliably renders labels, signage, and UI text, including non-Latin scripts |
| Prompt adherence (does what you ask) | High; prompt-engineering required less than older models | Moderate; benefits from Midjourney-specific prompt conventions | Variable; depends on fine-tuned model | High; particularly with structured prompts | High — gpt-image-2 plans the image with an LLM before rendering; strong on complex specs (charts, diagrams, multi-panel) |
| Commercial license / use rights | FLUX Pro: licensed via API providers (Replicate, Fal); commercial use OK. FLUX Dev: non-commercial only. FLUX Schnell: Apache 2.0 | Standard plan: limited commercial; Pro plan: broader commercial rights; check current terms | CreativeML Open RAIL-M license; commercial use generally OK with conditions | Generated images: customer owns subject to acceptable use policy | Generated images: customer owns; broad commercial use under OpenAI terms |
| Cost per image (API) | $0.005–$0.055 per image (FLUX Schnell to Pro) | Subscription only; ~$10–$60/month for varying generation volumes | $0 self-hosted; $0.002–$0.02 on hosted (Replicate, Fal) | ~$0.04 per image via Imagen API | Token-based: ~$0.006 (low) / ~$0.05 (medium) / ~$0.21 (high) per 1024px image |
| Self-hostable | FLUX Dev / Schnell: yes; FLUX Pro: no (API only) | No | Yes; the primary positioning of SDXL | No | No |
| API maturity | Strong; available via Replicate, Fal, BFL's own API | Limited API access (recent); Discord-first historically | Strong via multiple hosting providers | Strong via Google AI Studio / Vertex | Strong; native OpenAI API |
| Style consistency across images | Improving; FLUX Pro supports image-conditioning | Strong — Midjourney style refs and personalization features | Strong via LoRAs and ControlNet | Moderate; less specialised in style transfer | Good — high-fidelity image input supports edits and reference-based consistency |
| Speed (per image) | FLUX Schnell: under 2s; Pro: 5–15s | 10–30s typical | Variable; 2–10s on GPU | ~5–15s via API | Medium tier; varies with quality setting |
| Best for | Marketing creative, photorealistic product shots, commercial workflows | Stylised concept art, hero visuals, illustration-heavy work | Self-hosted workflows, customisation, niche style needs | Photorealism, integration with Google stack | Text-heavy creative (ads, social cards, UI mockups); editing workflows; teams already on OpenAI |
What to actually use
For high-volume commercial marketing creative with broad licensing — Flux Pro via Replicate or Fal. The aesthetic quality matches or beats Midjourney for most photorealistic work, the API is mature, and the commercial licensing through API providers is unambiguous. Trade-off: less aesthetic distinctiveness than Midjourney’s signature look. Right answer for ad creative, product photography, marketing-page hero images.
For stylised aesthetic or illustration work — Midjourney remains the leader. The “Midjourney look” is distinctive in a way the photorealism leaders aren’t; for concept art, mood boards, illustration-heavy marketing, this is the differentiator. Trade-off: API access is newer and less mature; licensing requires Pro plan for full commercial rights.
For self-hosted or maximally-customisable workflows — SDXL or FLUX Dev / Schnell. Self-hosting eliminates per-image cost and gives full control over the model (LoRAs, fine-tuning, custom styles). Trade-off: requires GPU infrastructure and engineering capacity; out-of-box quality below the hosted top tier. Right for high-volume operations or unique stylistic needs.
For teams in the Google ecosystem — Imagen via Google AI Studio or Vertex AI. Strong photorealism, well-integrated with the rest of Google’s AI tooling, sensible pricing. Right for teams already standardised on Google Cloud for AI workloads.
For teams already on OpenAI — gpt-image-2. This is no longer just a one-vendor-convenience pick: the April 2026 release is a major step up over gpt-image-1, with native 2K output, a single model for both generation and editing, and substantially improved photorealism. Trade-off: high-quality tier is the most expensive per-image option in this comparison (~$0.21), and there’s no self-hosting path.
For text-heavy images (advertisements, social cards, product photography with labels) — gpt-image-2 first, then Flux Pro or Imagen. gpt-image-2’s text engine is now the category leader — reliable spelling on labels, signage, and UI text, including non-Latin scripts. Flux Pro and Imagen handle short labels well; Midjourney still struggles with consistent text.
What you'll actually pay
The cost differences are small at the per-image level; the licensing differences are the practical decision driver. Pick on license fit and aesthetic, not on a few cents per image.
Volatility notes
This category moves quickly:
- Model refreshes. Each provider iterates roughly every 6–12 months; quality leaders shift accordingly.
- Licensing terms. Some providers have adjusted commercial terms repeatedly; verify current terms before committing to a workflow.
- Video extensions. Most image-model providers are extending into video. The image-to-video bridge is improving rapidly.
- Specialised models. Vertical-specific image models (medical, scientific, architectural) emerging from various labs.
Re-verify every 6 months. Pricing and licensing fine print drift the fastest.
Related work
For the workflow that generates social-media images at scale, see Hook generation for short-form video. For the broader creative-A/B-testing pattern that often consumes image generation, see Ad creative A/B testing at scale. For the alt-text generation that often pairs with image generation, see Generate alt text and image descriptions at scale. For the broader cost-vector framework, see Hidden costs of “free” AI tools.
FAQ
What about copyright and AI-generated images?
US law treats AI-generated images as not copyrightable in most cases — they're in the public domain unless meaningful human authorship is added (editing, composition, post-processing). For commercial use, this means competitors can copy your AI-generated images without legal exposure. Some teams add human editing on top of AI generation to create a stronger copyright claim. Talk to counsel for high-stakes commercial use.
Are AI-generated images legally safe to use commercially?
Mostly, with caveats. Two risks. (1) The model may have been trained on copyrighted material without licensing; lawsuits are ongoing. (2) The generated image may incidentally include trademarked elements (logos, character likenesses) you don't notice. The major providers have indemnification programmes for paying customers; check current terms. Don't generate intentional brand likenesses or copyrighted characters.
How do we ensure brand consistency across generated images?
Three patterns. (1) Style refs and image conditioning — feed example brand images, ask for consistency. (2) Custom-trained LoRAs or DreamBooth models for your brand aesthetic. (3) Style-guide prompts that explicitly describe the brand visual identity. Most teams use a combination; pure prompt-based consistency is unreliable, custom-trained models are more durable.
What about deepfakes and likenesses of real people?
All major commercial providers prohibit generating likenesses of real people without consent; many block this at the model level. The risk side is real — deepfake concerns are driving increasingly strict policies and legal scrutiny. Don't generate images of real people for commercial use; the legal and reputational exposure is high.