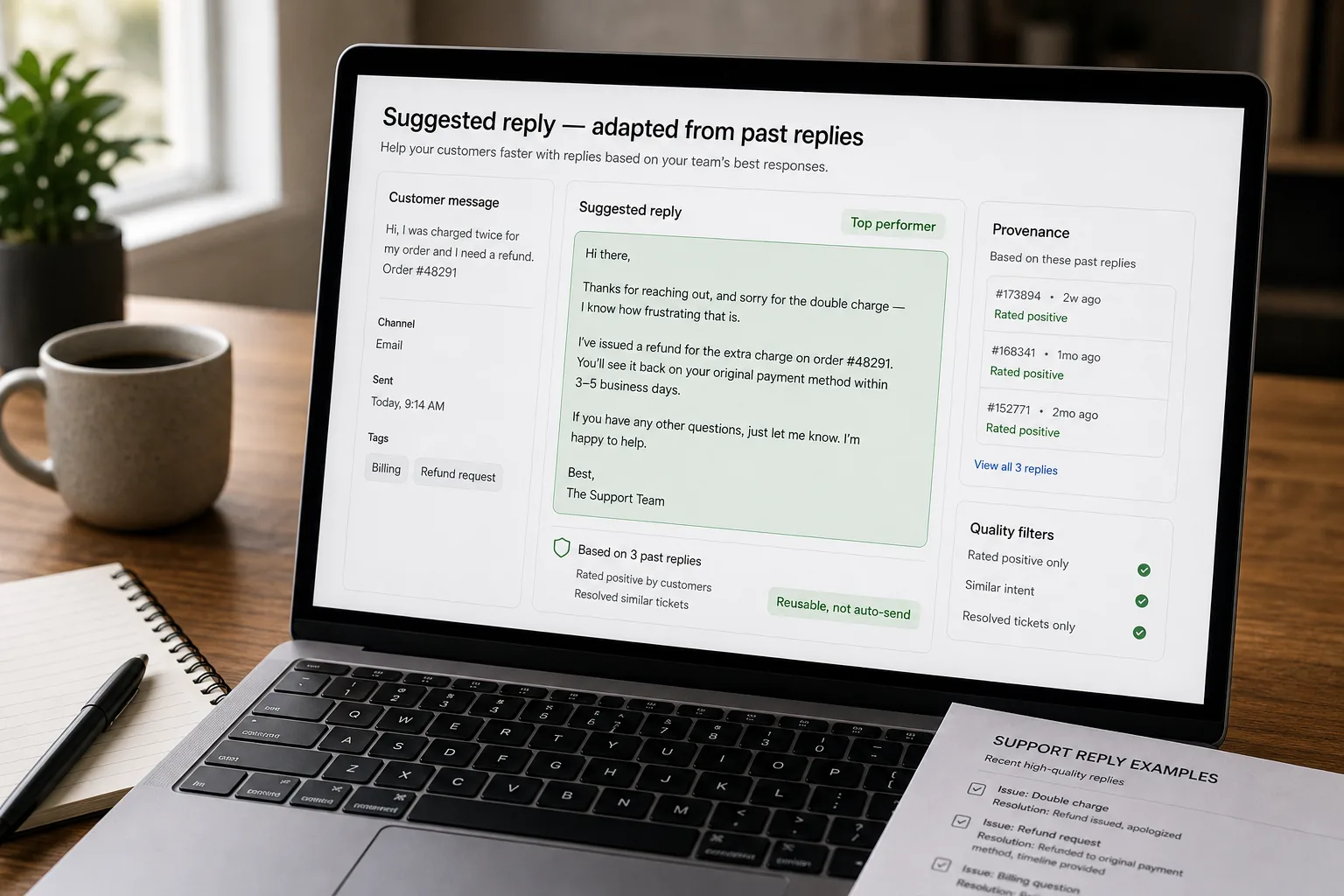
If you run a support team, the same five questions arrive in your inbox every week. Different customers, different phrasings, the same questions. The senior support rep who’s been here three years types the answer from memory in 90 seconds and moves on. The new rep who joined last month types a worse version of the same answer in 12 minutes, then double-checks it with the senior rep before sending.
The institutional knowledge of “what’s the right way to answer this” lives in the senior rep’s head, in previous answers buried in past tickets, and in docs that nobody reads as carefully as they did the first time.
The fix is to make the past answers retrievable. Convert every resolved ticket and reply into an embedding (a numeric representation of meaning). On a new inbound message, retrieve the most similar past replies and surface them as suggestions the agent can edit or send. The new rep gets the institutional voice. The senior rep gets faster on repeat questions. The team’s reply consistency improves without anyone writing a single FAQ entry.
This piece is the workflow — the embedding architecture, the context-aware retrieval, the suggestion-quality controls, and the feedback loop that keeps the suggestions current.
Where this fits — and where it doesn't
Use this if your team has 6+ months of past customer conversations (a corpus to learn from), your inbound volume includes a meaningful tail of repeat questions, and your team currently varies in reply quality / consistency. Common fits: support teams at scaling SaaS companies, customer success operations, sales-ops teams handling inbound qualification questions, founders’ inboxes with recurring partnership / press queries.
Don’t use this if your conversation corpus is small or noisy (under ~500 resolved tickets typically), your team needs every reply to be genuinely bespoke (high-end enterprise success motion), or your replies are mostly drafted from a knowledge base rather than from accumulated past replies. For the last case, the internal Q&A bot pattern is the right architecture; this pattern is for the team-replies side.
What you'll need before starting
- Access to your past conversation corpus — Intercom, Zendesk, Front, Help Scout, Gmail, or wherever your team’s resolved conversations live. The richer the corpus, the better the suggestions.
- A way to identify “good” past replies — typically resolved tickets where the customer didn’t reopen, replied “thanks”, or rated positively. Don’t train suggestions on every past reply; train on the ones that worked.
- A vector store — pgvector, Qdrant, Pinecone, or whatever your platform uses. See Vector databases compared.
- An LLM API for the suggestion-generation step. Cheap-tier models suffice; this is retrieval-augmented generation, not heavy reasoning.
- A helpdesk-integration path — most modern platforms (Intercom, Zendesk, Front) expose APIs for surfacing suggestions inline.
Six steps to suggestions agents will use
- Build the “good replies” corpus — quality-filter the past conversations
Don’t index every past reply; index the good ones. Filter by: customer didn’t reopen the ticket within 30 days, customer rated positively (where ratings exist), reply was from your team’s top performers, or reply was explicitly marked as a template-worthy answer. The corpus quality is the suggestion quality ceiling; including mediocre or wrong replies poisons the suggestions for everyone.
- Embed at the question-and-answer level, not the full-thread level
Most past tickets have multiple back-and-forth turns. Index each question-and-its-answer as a unit; don’t try to embed the whole thread. The unit of retrieval should match the unit of suggestion — when a new question comes in, you want similar past questions retrieved, not whole tangentially-related threads. Capture the customer’s question, the agent’s response, and minimal context (deal stage, customer tier, product area).
- Retrieve with hybrid search plus rerank
For each new inbound message, run semantic search (embedding similarity) and keyword search (BM25) in parallel, then rerank the combined candidates. Retrieve 20–30 candidates; rerank to the top 3–5 for the suggestion step. Hybrid plus rerank handles both the rephrased-question case (semantic) and the exact-terminology case (keyword); rerank picks the best across both.
- Generate the suggestion with the past reply as the template
Pass the top retrieved replies to the LLM as templates, along with the new customer’s context (their name, their product version, anything from the CRM that personalises the answer). The model adapts the past reply to the current customer’s situation; it doesn’t generate from scratch. This adaptation pattern is the differentiator from pure generation — the suggestion stays grounded in what your team has actually said, with personalisation as the only delta.
- Show suggestion confidence — low-confidence cases shouldn’t auto-fill
Each suggestion includes a confidence score derived from the rerank score of the top retrieved replies. High confidence: similar question, clear retrieval signal, suggest the adapted reply prominently. Medium: suggest with a “review carefully” flag. Low: don’t auto-fill anything; show the retrieved past replies as references but let the agent write from scratch. The confidence signal prevents the system from confidently suggesting wrong answers for genuinely-novel questions.
- Run the feedback loop — agent edits become training data
When agents edit a suggestion before sending, log the diff. When agents reject a suggestion entirely, log it. The edits and rejections are the training signal: heavily-edited suggestions tell you the retrieval missed; rejected suggestions tell you the past reply isn’t a current good template. Weekly, review the high-edit and high-rejection cases; update the corpus (remove stale replies, add new ones), retune the prompts. The feedback loop is what makes month six dramatically better than month one.
What it costs and what to expect
The acceptance rate is the operational signal; the new-agent ramp-time reduction is the strategic win for growing support teams.
Other ways to solve this
Helpdesk-bundled AI (Intercom Fin, Zendesk AI agents, Front AI, Help Scout AI). Increasingly bundle reply suggestions trained on your past conversations. Right answer for most teams — the integration is already done. Trade-off: less control over the corpus quality-filtering, sometimes opaque retrieval logic.
KB-grounded suggestions (not past-reply-grounded). Different architecture — generate replies from the knowledge base rather than from past replies. Right when your KB is comprehensive and current; doesn’t capture the team-voice in the same way. See draft customer support replies that hold up to scrutiny for the KB-grounded pattern; the two compose well.
Manual template library. Pre-AI approach — agents maintain a library of canned responses. Works at small scale; doesn’t capture nuance, doesn’t adapt per customer, gets stale fast. The AI pipeline learns the templates continuously rather than requiring manual maintenance.
Don’t suggest — train agents better. The traditional alternative. Strong agent training produces strong replies; the AI pipeline doesn’t replace training but reduces the ramp time meaningfully. Most teams use both — train on principles, use suggestions for execution.
Related work
For the KB-grounded reply pattern that complements this learned approach, see Draft customer support replies that hold up to scrutiny. For the embedding mechanics that power retrieval, see Embeddings explained without math. For the broader vector-store choice for the retrieval layer, see Vector databases compared. For pulling churn-signal patterns from the same conversation corpus, see Customer health scoring from product and support signals.
FAQ
How is this different from Intercom Fin or Zendesk AI agents?
Functionally overlapping; the bundled features increasingly do what this pattern describes. Build a custom layer when you need very specific corpus filtering, when you want to integrate with a helpdesk the bundled features don't fully cover, or when you want the retrieval-and-suggestion architecture exposed for non-customer-support use cases (sales, partnerships, internal communications). For pure support use cases on Intercom or Zendesk, the bundled features are usually sufficient.
What about conversations that contain customer PII?
Redact at indexing time. Strip names, emails, account IDs, payment details before embedding. The embedding doesn't lose meaningful retrieval power when generic placeholders replace PII; the personalisation at suggestion-generation time uses CRM context for the current customer, not the historical names. The redaction is the privacy guardrail; rely on it consistently.
How do we keep the corpus current as policies and product change?
Quarterly review with explicit deprecation. Mark replies older than a year for review; remove replies referencing deprecated products or policies. The corpus drifts toward staleness if nothing prunes it; the quarterly review prevents the slow-rot failure mode where suggestions confidently cite policies that changed last year.
Can we use this for sales-rep inboxes too?
Yes, with adjustments. The corpus is sales-rep past replies; the retrieval matches inbound sales questions; the suggestion generates a context-aware response. The mechanics are the same; the corpus content and the CRM context differ. Sales-rep suggestions need stronger personalisation (deal stage, prospect-specific context) than support suggestions typically do.
What if our team's past replies aren't great — we're trying to improve quality, not preserve current quality?
Two patterns. (1) Quality-filter aggressively to find the best 10–15% of past replies, train on those, even if it shrinks the corpus materially. (2) Pair with a KB-grounded approach for the cases where past replies aren't strong; the past-reply suggestion handles voice, the KB grounding handles accuracy. Don't train on a poor corpus expecting AI to improve it; the suggestions inherit the corpus's standard.